百度是如何判断WordPress企业网站内容优化质量度的
发布于
by
摘要:2017年百度出台了清风、飓风、闪电、今年上半年出台了烽火2.0、极乐、细雨。所有的站长都已知晓百度的策…
摘要:2017年百度出台了清风、飓风、闪电、今年上半年出台了烽火2.0、极乐、细雨。所有的站长都已知晓百度的策略,原创文章+移…
2017年百度出台了清风、飓风、闪电、今年上半年出台了烽火2.0、极乐、细雨。所有的站长都已知晓百度的策略,原创文章+移动端体验是百度近年重点着重的话题。那同时做为wordpress企业站长应该做到哪些规则才能保障到自身产品及流量的最大化,没错,当时是文案的质量。搜索引擎已经成为主要的搜索及信息收集主要来源途径。重复内容给用户造成了很大的困扰。我是卖车的,我就分析最新的车的配置,性价比,我是卖教育的,我就复制技术文章和干货文章,然而今天,百度对重复内容的判断一再升级,我们更应该去了解百度是如何判断内容重复度的。
比较常用的计算方法是通过页面分析把某些特定的信息标签化,然后通过两个页面的标签来进行对比,计划相似度,这种方法比较高效且简单,
比较合理百度这种少量信息应用场景的运算模式。
一、wordpress企业网站重复内容判断方法
第一、收集多个内容网页
第二、分别提取网页的正文内容
第三、抽取正文某段内容,并把内容标签化
第四、根据网站内容标签对比多个数据样本进行检索;
第六、根据网站类别进行数据计算
第七、根据附加标签判断每一类型下的内容内容是否重复。
通过以上的方式,简单的描述出了快速且有效的wordpress企业网站重复度在优化时的注意问题。
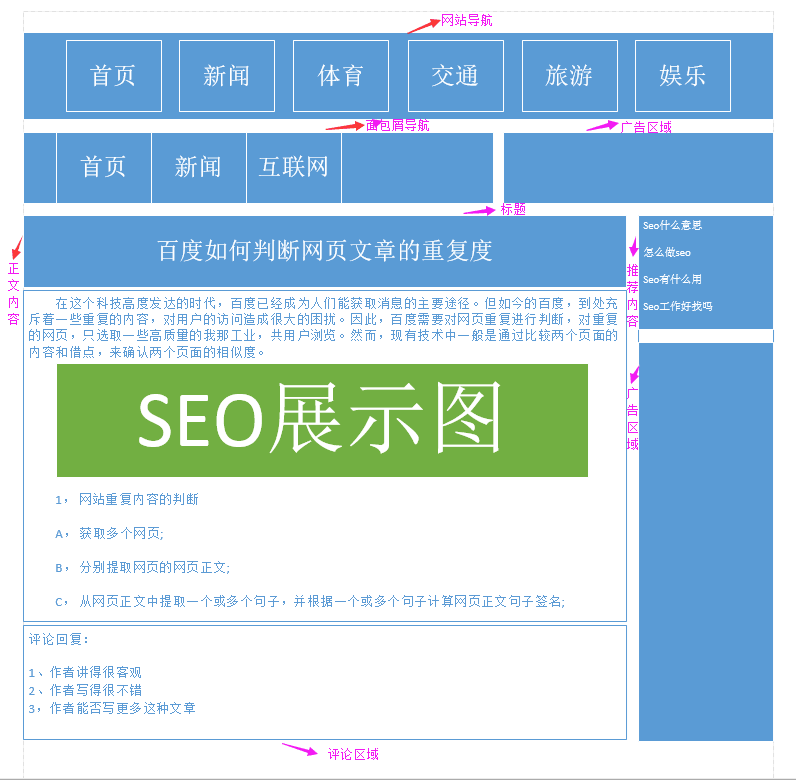
网页基本架构图
提取正文
A,对网页进行分块;
B,对分块后的网页进行块过滤,以获取包含网页正文的内容快;
C,从内容块中提取网页正文。
正文分句
A,对网页正文进行分句;
在本步骤中,可利用分号,句号,感叹号等表示句子完结的标志符号来对网页正文进行分句。此外,还可以通过网页正文的视觉信息来对网页正文进行分句。
B,对分句后的网页正文进行过滤及转换;
在步骤中,首先过滤掉句子中的数字信息;版权信息以及其他对网页重复判断不起决定性作用的信息。随后,对句子进行转换,例如,进行全角/半角转换或者繁体/简体转换,以使得转换后的句子的格式统一。
C,从过滤及转换后的网页正文中提取最长的一个或多个句子;
在本步骤中,过滤及转换后的网页正文提取出最长的一个句子或者做场的预定数量连续句子的组合。例如,某个网页实例中,经过过滤及转换后的某段最长,远超其他句子,因此可选择该段为网页正文句子,或者选择最长的连续句子组合作为网页正文句子。
D,对一个或多个句子进行hash签名运算,以获取网页正文句子签名。
总结:
1、两个网页的真实标题签名相同。
2、两个同行业网页内容标签是否相同。
3、两个网页的网页正文标签的不同位数小于6.。
4、两个网页的网页位置标签相同,并且url文件名签名相同。
5、评论块标签、资源标签、标签标题、摘要标签、url文件名标签中有三个标签相同。
附加信息整站判断重复标准:
通过两两页面比较,可以得到真重复url的集合。一般来说,如果这个真重复url集合中的网页的数量/整个网页集中网页的数量大于30%,则认为整个网页集都是真重复,否则就是假重复。
类别:WordPress教程、
本文收集自互联网,转载请注明来源。
如有侵权,请联系 wper_net@163.com 删除。
猜你喜欢GUESS YOU LIKE

还没有任何评论,赶紧来占个楼吧!